Rescribe is an easy-to-use desktop tool for performing OCR on image files, PDFs and Google Books. It uses the Tesseract OCR engine, combined with modern and efficient preprocessing and analysis pipelines, to produce high quality output. The tool has been built with a focus on OCR of historical printed works, but it includes modern language options and also works well on modern printed works.
rescribe 1.4.0 for Windows (2025-12-02)
rescribe 1.4.0 for Mac (2025-12-02)
rescribe 1.4.0 for Linux (alternative builds: wayland | flathub (recommended)) (2025-12-02)
Additional languages / scripts (optional)
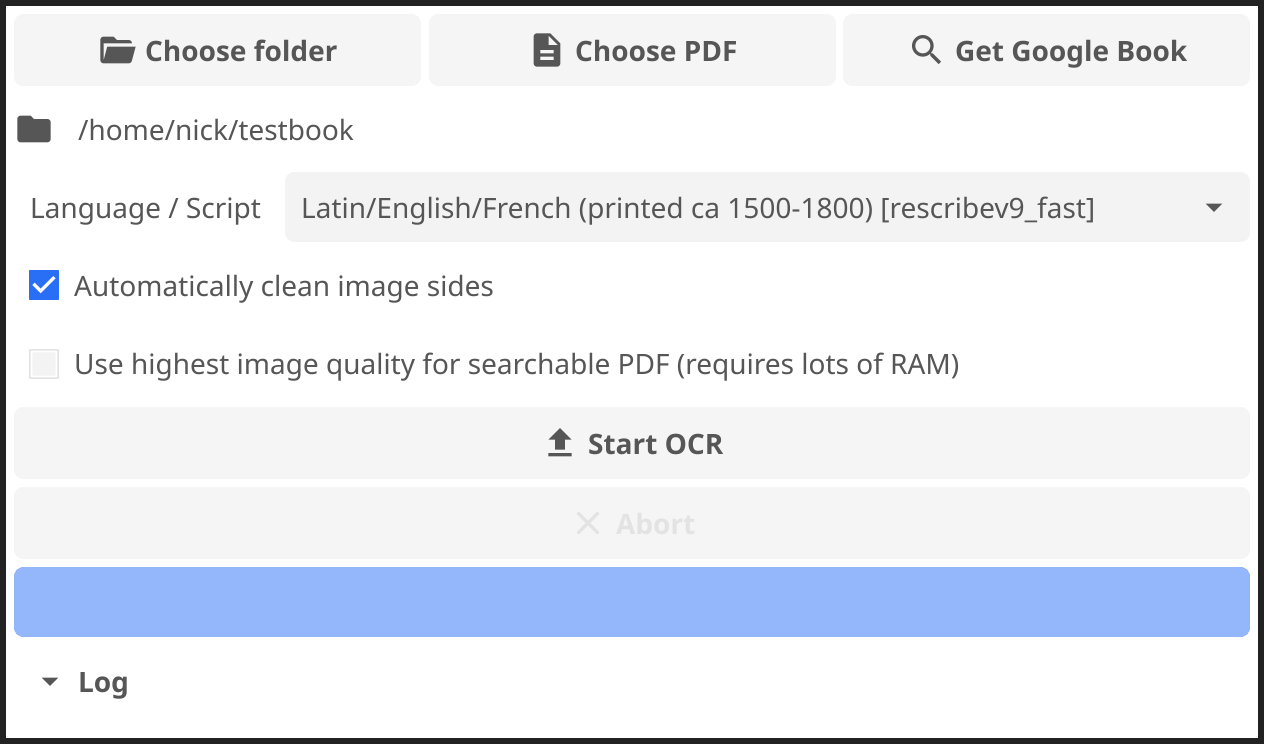
Simply choose a source – a folder, PDF file or Google Book –, select the appropriate language/script from the dropdown and hit “Start OCR”.
Mac Users may have to authorize the app for use in their Security settings after downloading the app. See below if you have difficulties.
Rescribe can also be used as a command-line tool, if you are so inclined, see command line usage for more details.
Once complete, rescribe creates several new files for each book:
mybook searchable.pdf), which is fully searchable.mybook.txt), which contains the full text from all pages in one file.text directory, containing plain text versions of the OCR results for each page.hocr directory, containing hOCR formatted OCR results for each page.graph.png file, which shows the OCR confidence of each page (a rough indicator of the quality of the OCR over the book).conf file, which lists the OCR confidence of each page, at each preprocessing binarisation threshold attempted.This software builds on previous work for the ERC-sponsored research project “The Normalization of Natural Philosophy” (University of Groningen). Further work on v1.0.0, in particular the graphical interface, was funded by a number of wonderful and generous people on Kickstarter. A huge thank you to everyone, in particular:
Ivy Livingston, Rachel Gruber, davidak, Jennifer Dekker, Ray Berger, Zdeněk Pavlátka, Damon, Kyle Foley, May, Gregory Fuller, Molly Ceglowski, Christopher Lu, Jorge Cajiao, John Levin, Brandon W. Hawk, Phillip Staniczenko, Rexforr
There are some PDFs that Rescribe can't extract images from successfully. If this happens, you will need to extract the images into a folder yourself, and choose that folder in the tool to OCR. You can use an online PDF image extractor to do this if necessary.
When you try to open Rescribe on MacOS for the first time, you may get a pop up with a message like this: "Rescribe" can't be opened because Apple cannot check it for malicious software. This is because we haven't paid Apple to be part of their developer programme. You can bypass it by holding the Control key and clicking on the app icon, then clicking Open. The warning message that then pops up will have an "Open" button. Click it to open Rescribe. You will only have to do this once; after that it will open as normal.
There was a known bug (fixed in v1.2.0) where input files with spaces in the filename can sometimes cause the process to fail. If you're having trouble, either update to v1.2.0 or later, or try renaming files to remove any spaces, for example rename Page 1.jpg to Page1.jpg.
If the app keeps failing for unintelligible reasons, please do get in touch at info@rescribe.xyz. If possible, include any messages posted to the “Log” section of the tool, to help us figure out what's up.
Rescribe is published under the GPLv3 license, and source code can be found by cloning its git repository with git clone https://git.rescribe.xyz/bookpipeline, or on github. It's written in Go, and is easy to hack on, if you have any patches or questions, please send them along to info@rescribe.xyz.
For more information on the inner workings of rescribe, take a look at our blog.